SAP ABAP — функциональные модули
Функциональные модули составляют основную часть системы SAP, поскольку в течение многих лет SAP создавала модульный код с использованием функциональных модулей, что позволяет повторно использовать код самим их разработчикам, а также их клиентам.
Функциональные модули — это подпрограммы, которые содержат набор многократно используемых операторов с параметрами импорта и экспорта. В отличие от программ «Включить», функциональные модули могут выполняться независимо. Система SAP содержит несколько предопределенных функциональных модулей, которые можно вызывать из любой программы ABAP. Функциональная группа действует как своего рода контейнер для ряда функциональных модулей, которые логически связаны друг с другом. Например, функциональные модули для системы начисления заработной платы персонала будут объединены в функциональную группу.
Чтобы посмотреть, как создавать функциональные модули, необходимо изучить конструктор функций. Вы можете найти построитель функций с кодом транзакции SE37. Просто введите часть имени функционального модуля со знаком подстановки, чтобы продемонстрировать, как можно искать функциональные модули. Введите * сумму *, а затем нажмите клавишу F4.
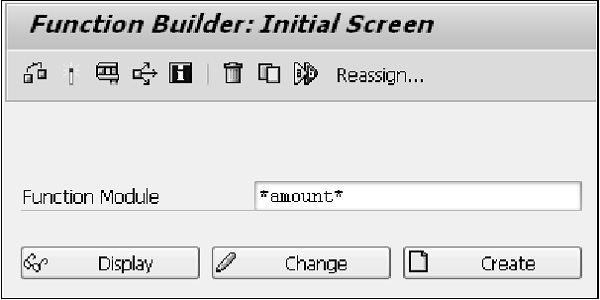
Результаты поиска будут отображены в новом окне. Функциональные модули отображаются в строках с синим фоном, а их функциональные группы — в розовых линиях. Далее вы можете посмотреть на группу функций ISOC, используя экран Навигатора объектов (Транзакция SE80). Вы можете увидеть список функциональных модулей, а также другие объекты, содержащиеся в функциональной группе. Давайте рассмотрим функциональный модуль SPELL_AMOUNT. Этот функциональный модуль преобразует числовые цифры в слова.
Создание новой программы
Шаг 1 — Перейдите к транзакции SE38 и создайте новую программу с именем Z_SPELLAMOUNT.
Шаг 2 — Введите некоторый код, чтобы можно было установить параметр, в котором значение можно было бы ввести и передать в функциональный модуль. Текстовый элемент text-001 здесь читается как «Введите значение».
Группу функций нельзя обработать sap
Перенос группы функций
| Почетный гуру |
 |
 |
Зарегистрирован:
Вт, апр 24 2007, 15:56
Сообщения: 1402
| PS Интересуют стандартные инструменты, SAPLink не предлагать )) |
| Почетный гуру |
|
 |
Зарегистрирован:
Пн, мар 28 2005, 15:38
Сообщения: 1209
| _________________ Часовой пояс: UTC + 3 часа Кто сейчас на конференцииСейчас этот форум просматривают: нет зарегистрированных пользователей |
| Вы не можете начинать темы Вы не можете отвечать на сообщения Вы не можете редактировать свои сообщения Вы не можете удалять свои сообщения Вы не можете добавлять вложения |
Логотип © 2006 Андрей Горшков
Поддержка: Кирилл Андреев, 2011-…
Иван Болховитинов
Небольшой периодический аудит в системе разработки, как и периодическое медицинское обследование не бывает лишним. Это может понадобиться, если вы:
В данной заметке делается обзор в части аудита групп функций и функциональных модулей.
Соглашение об именовании
Основное требование к именованию:
Это важная общая тема, касается всех разработок, а не только групп функций.
Сам SAP думает, что выделил диапазон имён Z_* для функциональных модулей клиента (знак подчёркивания). Однако большинство клиентов игнорирует это правило, и использует диапазон имён Z* по аналогии с другими объектами разработки.
Последнее проблемой не является, хотя случаются забавные накладки. Например, в одном из наших подпроектов использовался префикс ZGP_*, а потом оказалось есть родной функциональный модуль ZGP_DISPLAY и ещё парочка модулей с ним рядом.
Объединение в группы функций
Крайне не рекомендуется образование чрезмерно разнородных и укрупнённых групп функций, например:
Основная проблема чрезмерного объединения – это периодические проблемы при переносе. Например, если класть ведение всех-всех справочников в одну группу функций, то иногда всплывает следующий сценарий:
Если есть что-то похожее, то лучше при удобном случае раздробить группу функций на несколько мелких. При переприсвоении функционального модуля в другую группу функций будьте осторожны: группа функций может подразумевать использование общих данных или подпрограмм.
Если исторически так сложилось, но удобного случая не подворачивается – не переживайте, так и оставляйте. То что не сломалось, можно и не чинить.
Анализ использования
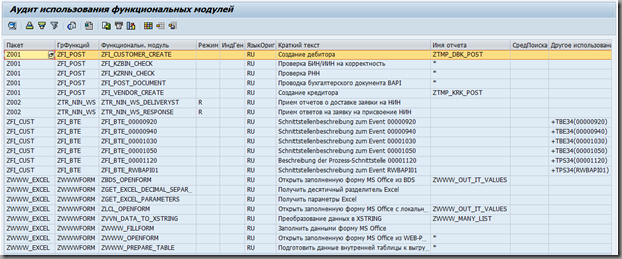
Часто можно встретить брошенные функциональные модули, в хорошей системе им не место. Но как же определить, что используется, а что не используется?
Дистанционные функциональные модули
Изнутри системы невозможно определить, что используется, а что нет. Это вопрос корректного межсистемного документирования.
У ответственного должно быть представление и документация, какие модули в какой системе могут использоваться, например:
Дистанционные функции могут использоваться и внутри системы, никто такого не запрещает (типа BAPI).
Прямое использование
Часть функциональных модулей может быть отслежена напрямую при помощи функции “Where is used”. Однако это годится только для статических упоминаний вызова.
Основные источники: программы, классы, средства поиска.
Динамические вызовы
Вызов функционального модуля может делаться в статическом стиле:
call function ‘ZK2_GET_USER’
importing
ev_ziin = lv_ziin.
Однако функцию можно вызвать и динамически:
lv_funcname = ‘ZK2_GET_USER’.
call function lv_funcname
importing
ev_ziin = lv_ziin.
Отследить такое использование уже гораздо сложнее.
Как правило такие вызовы всегда связаны с настройкой и расширением стандартной функциональности, и поэтому упоминание этих ФМ можно найти в соответствующих таблицах настройки:
По именованию и/или по интерфейсу часто можно догадаться об источнике вызова.
В обычной жизни я бы не рекомендовал использовать грубый динамический вызов (Z-from-Z) без осознанной необходимости.
Сгенерированные программы
SAP при прямом тесте ФМ генерирует служебные программы с именами следующего вида:
Проблемой это не является. Пусть себе лежат в уголочке.
Собственные функции вне Z-области
Практически SAP не запрещает создавать функции за пределами Z-области. Появляется простое надоедливое предупреждение, на которое мало кто читает.
Такое бывает в двух случаях:
Постарайтесь свести использование грубых экзитов к минимуму.
Сгенерированные модули должны существовать, пока существуют связанные объекты. Не путайте системе карты и не лезьте внутрь без явной необходимости.
Фронт работ
Если что-то нашли, то можно что-то и поделать:
Прочая работа над исходниками выходит за рамки данной заметки.
Замечания посткриптум
К особым исключениям можно отнести такие группы функций, которые являются скорее не сборником функциональных модулей, а сборником экранов. Это совсем другая опера, и те же генераторы ведения SM30 – гораздо ближе как раз к этой опере.
Десерт
Программа, которая мне помогает окинуть взглядом эту область: лежит тут.
Ах да … И если вы уж дочитали до этого места, то оставьте комментарий или личное сообщение.
Модульные тесты в ABAP. Часть третья. Всяческая суета
Эта статья ориентирована на ABAP-разработчиков в системах SAP ERP. Она содержит много специфических для платформы моментов, которые малоинтересны или даже спорны для разработчиков, использующих другие платформы.
Будем меряться
Считается, что главной метрикой качества тестов является покрытие. В разработческих интернетах часто можно встретить формулировки в стиле “полное покрытие”. Как правило, под полным покрытием понимается некий абсолют в 100.00%.
Процент покрытия – цифра сомнительная, ровно настолько же сомнительная, как и “средняя температура по больнице”. Процент покрытия по проекту – это среднее покрытие его частей. То есть: Модуль-1 имеет покрытие 80%, Модуль-2 имеет покрытие 20%, в среднем покрытие будет равно 50%, если допустить что модули примерно равны по содержимому. А верно ли что 80% в четыре раза лучше чем 20%?
Среднее бывает разное. В ABAP UNIT есть три различные метрики покрытия:
NB. Пул подпрограмм проще для демонстрации, чем группа функций или класс с методами. Пул подпрограмм описывается существенно меньшим количеством букв, чем класс. Параметры вынесены за рамки определений. В рамках этой маленькой демонстрации существенной разницы нет. И вообще: все переменные вымышлены, любые совпадения с продуктивным кодом случайны.
И предположим, что мы написали по одному простому тесту на каждую подпрограмму, функцию, метод. Для всех подпрограмм мы будем использовать значения [A = 7, B = 77].
NB: Пусть пока будет общая инициализация, а проверку результата опустим.
Procedure coverage
Это самый простой случай, можно посчитать на пальцах. Покрытие по процедурам будет 100% = ( 1 + 1 + 1 ) / ( 1 + 1 + 1 ) * 100.
Statement coverage
А если для тех же процедур мы посчитаем количество инструкций?
Каждая процедура содержит разное количество инструкций. Причём при заданных входных параметрах будут вызваны не все инструкции:
Если мы посчитаем метрику по инструкциям, то будет 71% = ( 3 + 5 + 2 ) / ( 3 + 8 + 3 ) * 100.
Рассмотрим работу метрики на DO_SOMETHING_ELSE. Инструменты разработки ABAP могут раскрасить строки исходного кода в соответствии с метрикой:

Наглядно, быстро, понятно. Просто удивительно, даже не ожидал такого от ABAP.
Из этой раскраски становится очевидно, что если бы мы взяли другие исходные параметры, то процент покрытия могу бы быть другим. В случае [A = 77, B = 7]:
При этом становится очевидным, что полного покрытия по данной метрике можно достичь только используя более одного тестового сценария. Например, при двух тестах [A = 77, B = 7] и [A = 7, B = 7777] всё позеленеет:
Таким образом метрика выходит на 100%. Можно ненадолго успокоиться.
Branch coverage
Эта метрика работает несколько сложнее. Она берёт все инструкции, которые могут вызвать ветвление, и проверяет их на то, что каждая такая инструкция выполняется в обе стороны.
Посмотрим на базе последнего примера:
Первая инструкция [IF A > B] на двух тестах отработала два раза: один раз по TRUE [A = 77, B = 7] и один раз по FALSE [A = 7, B = 7777].
А вот вторая инструкция [IF D > 1000] отработала только один раз на TRUE [A = 7, B = 7777].
Сам вызов функции считается за безусловную единицу, плюс первый IF даёт два из двух, второй IF даёт только единицу из двух. Значит наша метрика будет равна 80% = (1 + 2 + 1 ) / (1 + 2 + 2) * 100.
И тут уже выходит что для одной функции двух тестов уже мало, а нужно три. К предыдущим двум можно ещё добавить сценарий [A = 7, B = 77], чтобы второй IF отработал на FALSE.
После добавления третьего сценария метрика по этой функции вышла на 100%.
А что же с DO_NOTHING, спросите вы? Не существует такого теста, чтобы метрика по ветвям или инструкциям вышла на 100%. Очевидно, что функция требует рефакторинга, без которого выйти на полное покрытие не получится. Эту функцию следует или удалить, или она должна превратиться из DO_NOTHING в DO_SOMETHING_COMPLETELY_DIFFERENT.
Сто процентов!
Жаль нельзя написать ещё больше тестов и получить более 100%.
Понятно, что метрика Procedure coverage менее показательна в деталях. К ней можно внимательно присматриваться только на ранних этапах, если кода много а тестов ещё почти нет. А вот к какой метрике из двух оставшихся приглядываться после? Если первая метрика просто показывает насколько широко вы охватили функционал, то последние показывают, насколько вы его качественно охватили.
Как вы заметили, можно получить 100% по инструкциям, но при этом не будет 100% по ветвям. Но не наоборот (или я не могу придумать такой пример). Если вы уж получили 100% по ветвям, то значит вы зашли во все закоулки и все инструкции отработали. Но кому-то может показаться, что метрика по ветвям даёт менее показательные весовые коэффициенты в среднем, так как игнорирует один из явных весовых показателей – количество строк кода, то есть количество инструкций.
BTW: Да, пустая процедура даёт 100% показатели!
Уговор есть уговор
Для работы ABAP Unit неважно:
Следовательно, у нас по каждому пункту должна быть некоторая общая условная договорённость, облегчающая общее восприятие картины. Вроде соглашения по именованию или форматированию.
Тестовых классов должно быть ровно столько сколько нужно. Как минимум, каждый большой объект (группа функций, программа, класс) должен иметь один тестовый класс, можно больше.
Если у вас простая группа из нескольких связанных функций, то к ней достаточно и одного класса. А вот если в вашей группе есть шесть пачек малосвязанных функций, то здесь здесь должен скорее возникнуть вопрос “А сколько должно быть групп функций?”, а это тема для совсем другого разговора.
После корректного ответа на данный вопрос можно взять метод SETUP в качестве критерия делимости. Такой метод в классе должен быть один, вызывается он автоматически перед каждым тестовым методом.
Каждый сценарий должен дать отдельный тестовый метод, наименование метода должно прямо выводиться из тестируемого кода.
Один из принципов модульного тестирования: тестовый класс должен тестировать только тот код, в юрисдикции которого он находится. И хотя тесты могут находиться в любом месте исходного кода, но стоит отделять работающую функциональность от тестов.
Вот мастер для групп функций создаёт отдельную include-программу по предопределённому шаблону: например: LZFI_BTET99 для группы функций ZFI_BTE. Ничего плохого в этом не вижу, надо принимать за образец и продолжать в том же духе.
Также и в программах типа REPORT: пишите тесты строго в одной отдельной include-программе, с именем по шаблону.
Впрочем, никому не могу запретить писать всё вперемешку: код, его тест, код, его тест…
Когда?
Нельзя каждые пять минут запускать полный цикл модульных тестов. Но, как минимум, перед деблокированием запроса необходимо запускать тест причастных объектов.
Подытожу
Просто пачка тезисов для подведения черты:
Прямая реальная польза от тестов будет только в те моменты, когда по прошествии времени тесты будут провалены, когда кто-то будет допиливать эту функциональность.
Потому что умение правильно падать – самый лучший способ избежать травм. Если это верно для каратистов и велосипедистов, значит и для программистов тоже будет нелишним. Лучше правильно упасть плохо крутя педали, чем неправильно упасть хорошо крутя педали. Умение правильно падать важнее правильной экипировки.
А прямо сейчас можно извлечь только косвенную пользу:
ABAP Blog
Все о разработке в решениях от SAP
ABAP Blog
Все о разработке в решениях от SAP
Ссылки
Цитаты
Работая над проблемой, я никогда не думаю о красоте. Я думаю только о решении проблемы. Но если полученное решение некрасиво, я знаю, что оно неверно.
Р. Бакминстер Фуллер
(R. Buckminster Fuller)
Новое
Последние комментарии
Remote Function Call
Remote Function Call (RFC, удалённый вызов функций) – стандартный интерфейс для обмена данными между SAP и не SAP системами. Интерфейс передачи данных основан на CPI-C или TCP/IP. Стандартная справка по теме RFC или курс BC415.
Особенности RFC функций
Настроить назначение для RFC вызова можно через транзакцию SM59 (Таблица RFCDES). Подробнее о настройке RFC соединений можно посмотреть в курсе BC415.
Назначение RFC вызовов
Назначение RFC вызова определяется с помощью ключевого слова DESTINATION. В качестве параметра может принимать имя удаленной системы, SPACE, NONE, BACK.
Обработка исключений при вызовах RFC
При вызове RFC модуля могут возникать следующие исключения:
Типы RFC функций:
В случае, когда вы вызываете несколько sRFC подряд из одной группы функций, глобальные данные группы функций будут доступны до тех пор, пока не будет вызвана последняя функция из данной группы.
Если в sRFC внутри себя вызывает CALL SCREEN, CALL TRANSACTION или отображение списка, вызываемые экраны будут отображены в программе запустившей sRFC, но только если в SM59 указан диалоговый удаленный доступ, иначе система выдаст исключение SYSTEM_FAILURE.
Процедура не должна иметь в своем теле операторы, прерывающие выполнение программы, такие как: CALL SCREEN, SUBMIT, COMMIT WORK, WAIT, RFC вызовы, сообщения с типами W и I.
Пример программы запускающей 2 aRFC функции и ожидающей выполнение обоих:
Если в качестве имени задачи в вызове aRFC указать TASK3, условия выполнены не будут.
Пример распараллеливания вычислений с помощью групп:
aRFC вызовы так же как и sRFC могут вызывать внутри себя диалоги, но их использование в данном контексте выглядит сомнительно, более подробно рассмотрено в курсе (BC415).
Все tRFC вызовы сохраняются в таблицах: ARFCSSTATE и ARFCSDATA. Если вы не хотите вызывать tRFC немедленно после COMMIT WORK, вы можете вызвать ФМ START_OF_BACKGROUNDTASK (до COMMITWORK) и задать время и дату запуска для накопленных tRFC вызовов.
После выполнения COMMIT WORK в случае успешного локального обновления (в рамках LUW основной программы), накопленные данные создают фоновую задачу, в случае успешного выполнения этой задачи все данные из таблиц tRFC удаляются. Если задача не была выполнена, срабатывает механизм повтора или отката.
Так, например если связь с удаленной системой не была установлена, срабатывает автоматический повтор выполнения задания. По умолчанию количество повторов равно 30, интервал ожидания равен 15 минутам.
В случае если во втором из двух tRFC вызовов произошел сбой, сообщение с типом A или X или вызов исключения через RAISE после успешного выполнения первого происходит следующее:
Для принудительного отката всех изменений или отмены tRFC-LUW служит ФМ — RESTART_OF_BACKGROUNDTASK.
В случае если вызовы tRFC происходят на разных системах (DESTINATION ‘A’, DESTIONATION ‘B’), для каждой из них создается свой tRFC-LUW, вызовы tRFC группируются в зависимости от назначения.
Для вызова tRFC отдельно от остальных можно воспользоваться ключевым словом: AS SEPARATE UNIT.
Каждый tRFC-LUW имеет свой уникальный ID, для его получения можно использовать ФМ: ID_OF_BACKGROUNDTASK (вызывать перед COMMIT WORK). Используя данный ID можно определить статус для tRFC-LUW через ФМ — STATUS_OF_BACKGROUNDTASK.
Для размещения tRFC вызовов в порядке FIFO (первый пришел, первый вышел) необходимо перед каждым tRFC вызовом указывать имя очереди, делается это с помощью ФМ: TRFC_SET_QUEUE_NAME:
Имя очереди может содержать 24 символа, исключая % и *.
Для администрирования qRFC вместо транзакции SM58 используется транзакция — SMQ1. Таблица, в которой хранятся данные qRFC — TRFCQOUT.
Более подробная информация о bgRFC находится тут.
Транзакции, используемые при работе с RFC
BAPI функции
Для обмена бизнес данными, между SAP и не SAP системами, был создан так называемый Business Framework. Центральной его частью является хранилище бизнес объектов (BOR – Business Object Repository). Каждый бизнес объект обеспечивает объектно-ориентированный подход к хранению бизнес данных и работы с бизнес процессами. Например, вызывая методы бизнес объектов, мы тем самым манипулируем бизнес данными, за которые он отвечает, не заботясь о техническом вопросе (связях в таблицах и т.п.)
Бизнес объект состоит из следующих частей:
BAPI – реализация метода бизнес объекта, представляет собой функциональный модуль RFC. BAPI могут вызываться как синхронно (COMMIT WORK AND WAIT), так и асинхронно т.е. ожидая выполнения работы функции или нет.
BAPI могут представлять различные действия над объектом:
BAPI могут вызываться из различных приложений: офисных приложений (через VBA), JAVA и С++ программ и т.п.
Все BAPI после своей работы возвращают результат в виде внутренней таблицы с одной из структур: BAPIRETURN, BAPIRETURN1, BAPIRET1, BAPIRET2, BAPIRET1_FIX. В связи с этим в BAPI нет обработки исключений как в стандартных ФМ. Все эти структуры содержат в себе следующие поля:
Если транзакция выполнена успешно, то в таблице RETURN не будет существовать записей с типом ошибки «Е». Должно присутствовать сообщение с типом ошибки «S».
Обновление в BAPI всегда происходит в IN UPDATE TASK (см. документацию по ключевому слову IN UPDATE TASK или курс по обновлению БД – BC414). Внутри BAPI никогда не вызывается COMMIT WORK. Для подтверждения или отката LUW всегда должны использоваться ФМ: BAPI_TRANSCATION_COMMIT, BAPI_TRANSACTION_ROLLBACK, разница между данными ФМ и COMMIT WORK (ROLLBACK WORK) в том что они чистят внутренние переменные используемые при вызовах BAPI, если этого не делать могут возникать проблемы при повторном вызове BAPI. Все BAPI вызванные в программе до вызова BAPI_TRANSCATION_COMMIT (BAPI_TRANSCATION_ROLLBACK) вызываются в одном LUW. Для просмотра всех имеющихся в системе BAPI служит транзакция BAPI (запускает BAPI EXPLORER).
Курс, в котором рассматривается создание собственных BAPI — BC417.



