Содержание урока
§7. Дискретность
Дискретизация
§8. Алфавитный подход к оценке количества информации
§7. Дискретность
Дискретизация
Поскольку данные в компьютерах передаются с помощью дискретных сигналов, компьютеры могут хранить и обрабатывать только дискретную информацию, т. е. такую, которая может быть записана с помощью конечного количества знаков некоторого алфавита. Поэтому для ввода любых данных в компьютер их нужно перевести в дискретный код.
Дискретность означает, что мы представляем нечто целое (непрерывное) в виде набора отдельных элементов. Например, картина художника — это аналоговая (непрерывная) информация, а мозаика, сделанная на её основе (рисунок из кусочков разноцветного стекла), — дискретная. Множество вещественных чисел непрерывно (между любыми двумя различными числами есть ещё бесконечно много других), а множество целых чисел дискретно.
 Дискретизация — это представление единого объекта в виде множества отдельных элементов.
Дискретизация — это представление единого объекта в виде множества отдельных элементов.
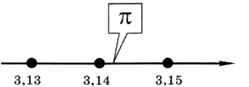
Всем известное иррациональное число л содержит бесконечное количество знаков в дробной части. Если мы хотим записать, чему равно π, необходимо остановиться на каком-то знаке, отбросив остальные, например: π ≈ 3,14. Таким образом, мы перешли к дискретной информации, потому что рассматриваем только числа с шагом 0,01 — точки на числовой оси (рис. 2.10).
Изменение высоты столбика термометра — это аналоговая информация, а записанная температура, округлённая до десятых долей градуса (например, 36,6°), — дискретная (рис. 2.11).
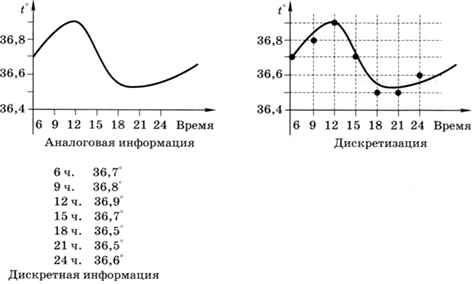
Дискретность состоит в том, что записанные значения температуры изменяются скачкообразно (через 0,1°), — это дискретизация по уровню, или квантование. Кроме того, обычно температуру больного измеряют не непрерывно, а несколько раз в день — появляется дискретизация по времени.
Заметим, что при дискретизации, как правило, происходит потеря информации. В данном случае мы, во-первых, потеряли информацию об изменении температуры между моментами измерений и, во-вторых, исказили измеренные значения, округлив их до десятых (каждая дискретизация, и по времени, и по уровню, вносит свою ошибку). Чтобы уменьшить ошибки, нужно уменьшить шаг дискретизации — измерять температуру чаще, записывать показания термометра до тысячных долей градуса. Однако в любой практической задаче есть некоторый предел, после которого увеличение точности уже никак не влияет на конечный результат.
Из приведённого примера понятно, что непрерывность или дискретность — это не свойство самой информации, а свойство её представления. В данном случае информация — это сведения об изменении температуры человека в течение дня. Если бы температура измерялась постоянно и записывалась самописцем (в виде графика), можно было бы говорить о том, что информация представлена в аналоговой (непрерывной) форме.
Ещё один пример — аналоговые («стрелочные») и цифровые вольтметры, которые измеряют одну и ту же величину, но выводят результат измерения в разном виде (рис. 2.12).

Теперь подумаем, как записать аналоговую величину, которая может принимать бесконечное множество значений. Вы уже знаете, что с помощью алфавита, состоящего из N символов, можно закодировать Q = разных сообщений длины L. Поэтому теоретически для записи аналоговой величины придется использовать бесконечное число знаков.
Итак, когда мы хотим записать (зафиксировать) информацию с помощью какого-то алфавита, нужно переходить к дискретному представлению. С одной стороны, это делает более надёжной передачу данных (если обе стороны одинаково понимают используемые знаки). С другой стороны, при дискретизации часть информации теряется.
Хотя аналоговую информацию невозможно точно представить в дискретном виде, при увеличении точности дискретизации свойства непрерывной и дискретной информации практически совпадают. Например, для точной записи числа тг требуется бесконечное количество цифр, но в расчётах чаще всего достаточно знать это значение с точностью не более 10 знаков.
Идеальная непрерывность существует только в теории. Мы считаем дерево, пластмассу, металл непрерывными, но на самом деле они состоят из отдельных молекул, расположенных на некотором расстоянии друг от друга, — это значит, что вещество дискретно. Иллюстрация в книге кажется нам сплошной, но при сильном увеличении видно, что она строится из отдельных точек (имеет «растр») (рис. 2.13).

«Плёночная» фотография считается аналоговой, но при увеличении снимка с фотоплёнки нельзя бесконечно получать все новые и новые детали — предел «уточнения» определяется величиной зерна светочувствительного материала.
Мы часто воспринимаем дискретные объекты как непрерывные, потому что наши органы чувств не позволяют различить отдельные элементы. Например, разрешающая способность глаза составляет около одной угловой минуты (1′ = 1/60 часть градуса), это значение определяется размером элементов сетчатки глаза. Поэтому человек не может различить два объекта, если направления на них различаются меньше, чем на 1′. Для того чтобы повысить разрешающую способность при наблюдении, применяют специальные приборы (например, бинокли и микроскопы).
Следующая страница  Вопросы и задания
Вопросы и задания
Cкачать материалы урока
Сжатие информации без потерь. Часть первая
Доброго времени суток.
Сегодня я хочу коснуться темы сжатия данных без потерь. Несмотря на то, что на хабре уже были статьи, посвященные некоторым алгоритмам, мне захотелось рассказать об этом чуть более подробно.
Я постараюсь давать как математическое описание, так и описание в обычном виде, для того, чтобы каждый мог найти для себя что-то интересное.
В этой статье я коснусь фундаментальных моментов сжатия и основных типов алгоритмов.
Сжатие. Нужно ли оно в наше время?
Разумеется, да. Конечно, все мы понимаем, что сейчас нам доступны и носители информации большого объема, и высокоскоростные каналы передачи данных. Однако, одновременно с этим растут и объемы передаваемой информации. Если несколько лет назад мы смотрели 700-мегабайтные фильмы, умещающиеся на одну болванку, то сегодня фильмы в HD-качестве могут занимать десятки гигабайт.
Конечно, пользы от сжатия всего и вся не так много. Но все же существуют ситуации, в которых сжатие крайне полезно, если не необходимо.
Конечно, можно придумать еще множество различных ситуаций, в которых сжатие окажется полезным, но нам достаточно и этих нескольких примеров.
Все методы сжатия можно разделить на две большие группы: сжатие с потерями и сжатие без потерь. Сжатие без потерь применяется в тех случаях, когда информацию нужно восстановить с точностью до бита. Такой подход является единственно возможным при сжатии, например, текстовых данных.
В некоторых случаях, однако, не требуется точного восстановления информации и допускается использовать алгоритмы, реализующие сжатие с потерями, которое, в отличие от сжатия без потерь, обычно проще реализуется и обеспечивает более высокую степень архивации.
| Сжатие с потерями |
| Лучшие степени сжатия, при сохранении «достаточно хорошего» качества данных. Применяются в основном для сжатия аналоговых данных — звука, изображений. В таких случаях распакованный файл может очень сильно отличаться от оригинала на уровне сравнения «бит в бит», но практически неотличим для человеческого уха или глаза в большинстве практических применений. |
| Сжатие без потерь |
| Данные восстанавливаются с точностью до бита, что не приводит к каким-либо потерям информации. Однако, сжатие без потерь показывает обычно худшие степени сжатия. |
Итак, перейдем к рассмотрению алгоритмов сжатия без потерь.
Универсальные методы сжатия без потерь
В общем случае можно выделить три базовых варианта, на которых строятся алгоритмы сжатия.
Первая группа методов – преобразование потока. Это предполагает описание новых поступающих несжатых данных через уже обработанные. При этом не вычисляется никаких вероятностей, кодирование символов осуществляется только на основе тех данных, которые уже были обработаны, как например в LZ – методах (названных по имени Абрахама Лемпеля и Якоба Зива). В этом случае, второе и дальнейшие вхождения некой подстроки, уже известной кодировщику, заменяются ссылками на ее первое вхождение.
Вторая группа методов – это статистические методы сжатия. В свою очередь, эти методы делятся на адаптивные (или поточные), и блочные.
В первом (адаптивном) варианте, вычисление вероятностей для новых данных происходит по данным, уже обработанным при кодировании. К этим методам относятся адаптивные варианты алгоритмов Хаффмана и Шеннона-Фано.
Во втором (блочном) случае, статистика каждого блока данных высчитывается отдельно, и добавляется к самому сжатому блоку. Сюда можно отнести статические варианты методов Хаффмана, Шеннона-Фано, и арифметического кодирования.
Третья группа методов – это так называемые методы преобразования блока. Входящие данные разбиваются на блоки, которые затем трансформируются целиком. При этом некоторые методы, особенно основанные на перестановке блоков, могут не приводить к существенному (или вообще какому-либо) уменьшению объема данных. Однако после подобной обработки, структура данных значительно улучшается, и последующее сжатие другими алгоритмами проходит более успешно и быстро.
Общие принципы, на которых основано сжатие данных
Все методы сжатия данных основаны на простом логическом принципе. Если представить, что наиболее часто встречающиеся элементы закодированы более короткими кодами, а реже встречающиеся – более длинными, то для хранения всех данных потребуется меньше места, чем если бы все элементы представлялись кодами одинаковой длины.
Точная взаимосвязь между частотами появления элементов, и оптимальными длинами кодов описана в так называемой теореме Шеннона о источнике шифрования(Shannon’s source coding theorem), которая определяет предел максимального сжатия без потерь и энтропию Шеннона.
Немного математики
Если вероятность появления элемента si равна p(si), то наиболее выгодно будет представить этот элемент — log2p(si) битами. Если при кодировании удается добиться того, что длина всех элементов будет приведена к log2p(si) битам, то и длина всей кодируемой последовательности будет минимальной для всех возможных методов кодирования. При этом, если распределение вероятностей всех элементов F = 
Это значение называют энтропией распределения вероятностей F, или энтропией источника в заданный момент времени.
Однако обычно вероятность появления элемента не может быть независимой, напротив, она находится в зависимости от каких-то факторов. В этом случае, для каждого нового кодируемого элемента si распределение вероятностей F примет некоторое значение Fk, то есть для каждого элемента F= Fk и H= Hk.
Иными словами, можно сказать, что источник находится в состоянии k, которому соответствует некий набор вероятностей pk(si) для всех элементов si.
Поэтому, учитывая эту поправку, можно выразить среднюю длину кодов как
Где Pk — вероятность нахождения источника в состоянии k.
Итак, на данном этапе мы знаем, что сжатие основано на замене часто встречающихся элементов короткими кодами, и наоборот, а так же знаем, как определить среднюю длину кодов. Но что же такое код, кодирование, и как оно происходит?
Кодирование без памяти
Коды без памяти являются простейшими кодами, на основе которых может быть осуществлено сжатие данных. В коде без памяти каждый символ в кодируемом векторе данных заменяется кодовым словом из префиксного множества двоичных последовательностей или слов.
На мой взгляд, не самое понятное определение. Рассмотрим эту тему чуть более подробно.
Пусть задан также другой алфавит. Аналогично, обозначим слово в этом алфавите как B.
Введем еще два обозначения для множества всех непустых слов в алфавите. Пусть — количество непустых слов в первом алфавите, а — во втором.
Пусть также задано отображение F, которое ставит в соответствие каждому слову A из первого алфавита некоторое слово B=F(A) из второго. Тогда слово B будет называться кодом слова A, а переход от исходного слова к его коду будет называться кодированием.
Поскольку слово может состоять и из одной буквы, то мы можем выявить соответствие букв первого алфавита и соответствующих им слов из второго:
a1 B1
a2 B2
…
an Bn
Это соответствие называют схемой, и обозначают ∑.
В этом случае слова B1, B2,…, Bn называют элементарными кодами, а вид кодирования с их помощью — алфавитным кодированием. Конечно, большинство из нас сталкивались с таким видом кодирования, пусть даже и не зная всего того, что я описал выше.
Итак, мы определились с понятиями алфавит, слово, код, и кодирование. Теперь введем понятие префикс.
Пусть слово B имеет вид B=B’B». Тогда B’ называют началом, или префиксом слова B, а B» — его концом. Это довольно простое определение, но нужно отметить, что для любого слова B, и некое пустое слово ʌ («пробел»), и само слово B, могут считаться и началами и концами.
Итак, мы подошли вплотную к пониманию определения кодов без памяти. Последнее определение, которое нам осталось понять — это префиксное множество. Схема ∑ обладает свойством префикса, если для любых 1≤i, j≤r, i≠j, слово Bi не является префиксом слова Bj.
Проще говоря, префиксное множество – это такое конечное множество, в котором ни один элемент не является префиксом (или началом) любого другого элемента. Простым примером такого множества является, например, обычный алфавит.
Одним из канонических алгоритмов, которые иллюстрируют данный метод, является алгоритм Хаффмана.
Алгоритм Хаффмана
Алгоритм Хаффмана использует частоту появления одинаковых байт во входном блоке данных, и ставит в соответствие часто встречающимся блокам цепочки бит меньшей длины, и наоборот. Этот код является минимально – избыточным кодом. Рассмотрим случай, когда, не зависимо от входного потока, алфавит выходного потока состоит из всего 2 символов – нуля и единицы.
Для лучшей иллюстрации, рассмотрим небольшой пример.
Пусть у нас есть алфавит, состоящий из всего четырех символов — < a1, a2, a3, a4>. Предположим также, что вероятности появления этих символов равны соответственно p1=0.5; p2=0.24; p3=0.15; p4=0.11 (сумма всех вероятностей, очевидно, равна единице).
Итак, построим схему для данного алфавита.
Если сделать иллюстрацию этого процесса, получится примерно следующее:
Как вы видите, при каждом объединении мы присваиваем объединяемым символам коды 0 и 1.
Таким образом, когда дерево построено, мы можем легко получить код для каждого символа. В нашем случае коды будут выглядить так:
Поскольку ни один из данных кодов не является префиксом какого-нибудь другого (то есть, мы получили пресловутое префиксное множество), мы можем однозначно определить каждый код в выходном потоке.
Итак, мы добились того, что самый частый символ кодируется самым коротким кодом, и наоборот.
Если предположить, что изначально для хранения каждого символа использовался один байт, то можно посчитать, насколько нам удалось уменьшить данные.
Пусть на входу у нас была строка из 1000 символов, в которой символ a1 встречался 500 раз, a2 — 240, a3 — 150, и a4 — 110 раз.
Изначально данная строка занимала 8000 бит. После кодирования мы получим строку длинной в ∑pili = 500 * 1 + 240 * 2 + 150 * 3 + 110 * 3 = 1760 бит. Итак, нам удалось сжать данные в 4,54 раза, потратив в среднем 1,76 бита на кодирование каждого символа потока.
Напомню, что согласно Шеннону, средняя длина кодов составляет . Подставив в это уравнение наши значения вероятностей, мы получим среднюю длину кодов равную 1.75496602732291, что весьма и весьма близко к полученному нами результату.
Тем не менее, следует учитывать, что помимо самих данных нам необходимо хранить таблицу кодировки, что слегка увеличит итоговый размер закодированных данных. Очевидно, что в разных случаях могут с использоваться разные вариации алгоритма – к примеру, иногда эффективнее использовать заранее заданную таблицу вероятностей, а иногда – необходимо составить ее динамически, путем прохода по сжимаемым данным.
Заключение
Итак, в этой статье я постарался рассказать об общих принципах, по которым происходит сжатие без потерь, а также рассмотрел один из канонических алгоритмов — кодирование по Хаффману.
Если статья придется по вкусу хабросообществу, то я с удовольствием напишу продолжение, так как есть еще множество интересных вещей, касающихся сжатия без потерь; это как классические алгоритмы, так и предварительные преобразования данных (например, преобразование Барроуза-Уилира), ну и, конечно, специфические алгоритмы для сжатия звука, видео и изображений (самая, на мой взгляд, интересная тема).
Сжатие изображений с потерями
Прежде чем говорить об алгоритмах сжатиях с потерями, необходимо договориться о том, что считать приемлемыми потерями. Понятно, что главным критерием остаётся визуальная оценка изображения, но также изменения в сжатом изображении могут быть оценены количественно. Самый простой способ оценки – это вычисление непосредственной разности сжатого и исходного изображений. Договоримся, что под  мы будем понимать пиксел, находящийся на пересечении i-ой строки и j-ого столбца исходного изображения, а под
мы будем понимать пиксел, находящийся на пересечении i-ой строки и j-ого столбца исходного изображения, а под  — соответствующий пиксел сжатого изображения. Тогда для любого пиксела можно легко определить ошибку кодирования
— соответствующий пиксел сжатого изображения. Тогда для любого пиксела можно легко определить ошибку кодирования  , а для всего изображения, состоящего из N строк и M столбцов, можно вычислить суммарную ошибку
, а для всего изображения, состоящего из N строк и M столбцов, можно вычислить суммарную ошибку  . Очевидно, что, чем больше суммарная ошибка, тем сильнее искажения на сжатом изображении. Тем не менее, эту величину крайне редко используют на практике, т.к. она никак не учитывает размеры изображения. Гораздо шире применяется оценка с использованием среднеквадратичного отклонения
. Очевидно, что, чем больше суммарная ошибка, тем сильнее искажения на сжатом изображении. Тем не менее, эту величину крайне редко используют на практике, т.к. она никак не учитывает размеры изображения. Гораздо шире применяется оценка с использованием среднеквадратичного отклонения 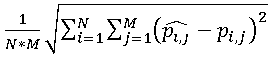 .
.
Другой (хотя и близкий по сути) подход заключается в следующем: пиксели итогового изображения рассматриваются как сумма пикселей исходного изображения и шума. Критерием качества при таком подходе называют величину отношения сигнал-шум (SNR), вычисляемую следующим образом: 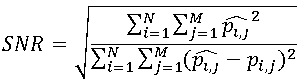 .
.
Обе эти оценки являются т.н. объективными критериями верности воспроизведения, т.к. зависят исключительно от исходного и сжатого изображения. Тем не менее, эти критерии не всегда соответствуют субъективным оценкам. Если изображения предназначены для восприятия человеком, единственное, что можно утверждать: плохие показатели объективных критериев чаще всего соответствуют низким субъективным оценкам, в то же время хорошие показатели объективных критериев вовсе не гарантируют высоких субъективных оценок.
С процессом квантования и дискретизации связано понятие визуальной избыточности. Значительная часть информации на изображении не может быть воспринята человеком: например, человек способен замечать незначительные перепады яркости, но гораздо менее чувствителен к цветности. Также, начиная с определённого момента, повышение точности дискретизации не влияет на визуальное восприятие изображения. Таким образом, некоторая часть информации может быть удалена без ухудшения визуального качества. Такую информацию называют визуально избыточной.
Самым простым способом удаления визуальной избыточности является уменьшение точности дискретизации, но на практике этот способ можно применять только для изображений с простой структурой, т.к. искажения, возникающие на сложных изображениях, слишком заметны (см. Табл. 1)
Для удаления избыточной информации чаще уменьшают точность квантования, но нельзя уменьшать её бездумно, т.к. это приводит к резкому ухудшению качества изображения.
Рассмотрим уже известное нам изображение с. Предположим, что изображение представлено в цветовом пространстве RGB, результаты кодирования этого изображения с пониженной точностью квантования представлены в Табл. 2.

В рассмотренном примере используется равномерное квантование как наиболее простой способ, но, если важно более точно сохранить цветопередачу, можно использовать один из следующих подходов: либо использовать равномерное квантование, но значением закодированной яркости выбирать не середину отрезка, а математическое ожидание яркости на этом отрезке, либо использовать неравномерное разбиение всего диапазона яркостей.
Внимательно изучив полученные изображения, можно заметить, что на сжатых изображениях возникают отчётливые ложные контуры, которые значительно ухудшают визуальное восприятие. Существуют методы, основанные на переносе ошибки квантования в следующий пиксел, позволяющие значительно уменьшить или даже совсем удалить эти контуры, но они приводят к зашумлению изображения и появлению зернистости. Перечисленные недостатки сильно ограничивают прямое применение квантования для сжатия изображений.
Большинство современных методов удаления визуально избыточной информации используют сведения об особенностях человеческого зрения. Всем известна различная чувствительность человеческого глаза к информации о цветности и яркости изображения. В Табл. 3 показано изображение в цветовом пространстве YIQ, закодированное с разной глубиной квантования цветоразностных сигналов IQ:
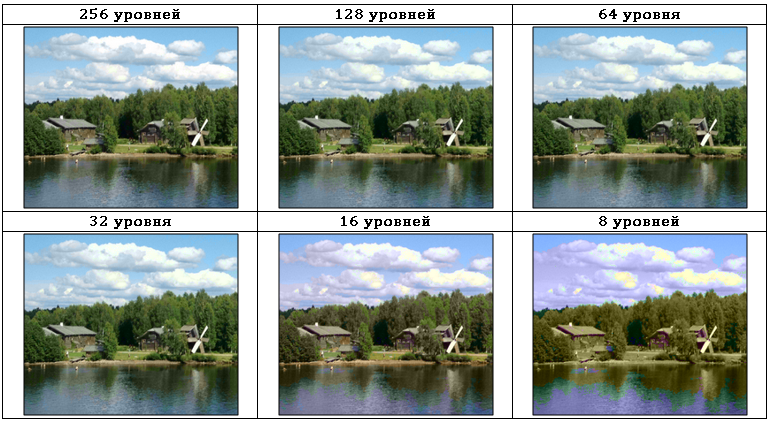
Как видно из Табл. 3, глубина квантования цветоразностных сигналов может быть понижена с 256 до 32 уровней с минимальными визуальными изменениями. В то же время потери в I и Q составляющих весьма существенны и показаны в Табл. 4

Несмотря на простоту описанных методов, в чистом виде они применяются редко, чаще всего они служат одним из шагов более эффективных алгоритмов.
Кодирование с предсказанием
Мы уже рассматривали кодирование с предсказанием как весьма эффективный метод сжатия информации без потерь. Если совместить кодирование с предсказанием и сжатие посредством квантования, получится весьма простой и эффективный алгоритм сжатия изображения с потерями. В рассматриваемом методе будет квантоваться ошибка предсказания. Именно точность её квантования будет определять как степень сжатия, так и искажения, вносимые в сжатое изображение. Выбор оптимальных алгоритмов для предсказания и для квантования — довольно сложная задача. На практике широко используют следующие универсальные (обеспечивающие приемлемое качество на большинстве изображений) предсказатели:

Мы же в свою очередь подробно рассмотрим самый простой и в тоже время весьма популярный способ кодирования с потерями – т.н. дельта-модуляцию. Этот алгоритм использует предсказание на основе одного предыдущего пиксела, т.е.  . Полученная после этапа предсказания ошибка квантуется следующим образом:
. Полученная после этапа предсказания ошибка квантуется следующим образом:
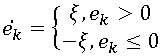
На первый взгляд это очень грубый способ квантования, но у него есть одно неоспоримое преимущество: результат предсказания может быть закодирован единственным битом. В Табл. 5 показаны изображения, закодированные с помощью дельта-модуляции (обход по строкам) с различными значениями ξ.

Наиболее заметны два вида искажений – размытие контуров и некая зернистость изображения. Это наиболее типичные искажения, возникающие из-за перегрузки по крутизне и из-за т.н. шума гранулярности. Такие искажения характерны для всех вариантов кодирования с потерями с предсказанием, но именно на примере дельта-модуляции они видны лучше всего.
Шум гранулярности возникает в основном на однотонных областях, когда значение ξ слишком велико для корректного отображения малых колебаний яркости (или их отсутствия). На Рис. 1 жёлтой линией отмечена исходная яркость, а синие столбцы показывают шум, возникающий при квантовании ошибки предсказания.
Ситуация перегрузки по крутизне принципиально отличается от ситуации с шумом гранулярности. В этом случае величина ξ оказывается слишком малой для передачи резкого перепада яркости. Из-за того, что яркость закодированного изображения не может расти также быстро, как яркость исходного изображения, возникает заметная размытость контуров. Ситуация с перегрузкой по крутизне поясняется на Рис. 2
Легко заметить, что шум гранулярности уменьшается вместе с уменьшением ξ, но вместе с этим растут искажения из-за перегрузки по крутизне и наоборот. Это приводит к необходимости оптимизации величины ξ. Для большинства изображений рекомендуется выбирать ξ∈[5;7].
Трансформационное кодирование
Все рассмотренные ранее методы сжатия изображений работали непосредственно с пикселами исходного изображения. Такой подход называют пространственным кодированием. В текущем разделе мы рассмотрим принципиально иной подход, называемый трансформационным кодированием.
Основная идея подхода похожа на рассмотренный ранее способ сжатия с использованием квантования, но квантоваться будут не значения яркостей пикселов, а специальным образом рассчитанные на их основе коэффициенты преобразования (трансформации). Схемы трансформационного сжатия и восстановления изображений приведены на Рис. 3, Рис. 4.
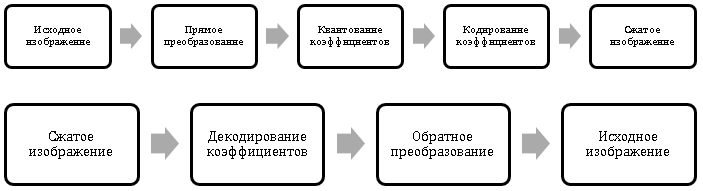
Непосредственно сжатие происходит не в момент кодирования, а в момент квантования коэффициентов, т.к. для большинства реальных изображений большая часть коэффициентов может быть грубо квантована.
Для получения коэффициентов используют обратимые линейные преобразования: например преобразование Фурье, дискретное косинусное преобразование или преобразование Уолша-Адамара. Выбор конкретного преобразования зависит от допустимого уровня искажения и имеющихся ресурсов.
В общем случае изображение размерами N*N пикселов рассматривается как дискретная функция от двух аргументов I(r,c), тогда прямое преобразование можно выразить в следующем виде:

Набор  как раз и является искомым набором коэффициентов. На основе этого набора можно восстановить исходное изображение, воспользовавшись обратным преобразованием:
как раз и является искомым набором коэффициентов. На основе этого набора можно восстановить исходное изображение, воспользовавшись обратным преобразованием:
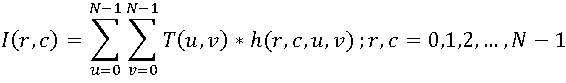
Функции  называют ядрами преобразования, при этом функция g – ядро прямого преобразования, а функция h — ядро обратного преобразования. Выбор ядра преобразования определяет как эффективность сжатия, так и вычислительные ресурсы, требуемые для выполнения преобразования.
называют ядрами преобразования, при этом функция g – ядро прямого преобразования, а функция h — ядро обратного преобразования. Выбор ядра преобразования определяет как эффективность сжатия, так и вычислительные ресурсы, требуемые для выполнения преобразования.
Широкораспространённые ядра преобразования
Наиболее часто при трансформационном кодировании используются ядра, перечисленные ниже.
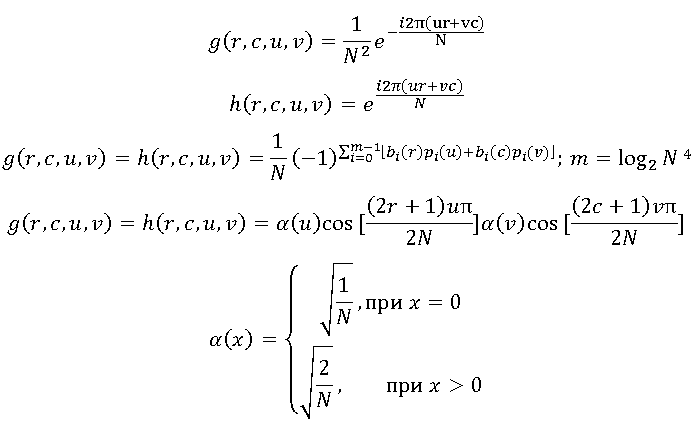
Использование первых двух ядер этих ядер приводит к упрощённому варианту дискретного преобразования Фурье. Вторая пара ядер соответствует довольно часто используемому преобразованию Уолша-Адамара. И, наконец, наиболее распространённым преобразованием является дискретное косинусное преобразование:
Широкая распространённость дискретного косинусного преобразования обусловлена его хорошей способностью производить уплотнение энергии изображения. Строго говоря, есть более эффективные преобразования. Например, преобразование Кархунена-Лоэва имеет наилучшую эффективность в плане уплотнения энергии, но его сложность практически исключает возможность широкого практического применения.
Сочетание эффективности уплотнения энергии и сравнительной простоты реализации сделало дискретное косинусное преобразование стандартом трансформационного кодирования.
Графическое пояснение трансформационного кодирования
В контексте функционального анализа рассмотренные преобразования можно рассматривать как разложение по набору базисных функций. В то же время в контексте обработки изображений эти преобразования можно воспринимать как разложение по базисным изображениям. Чтобы пояснить эту идею, рассмотрим квадратное изображение I размером n*n пикселов. Ядра преобразований не зависят ни от коэффициентов преобразования, ни от значения пикселов исходного изображения, поэтому обратное преобразование можно записать в матричном виде:

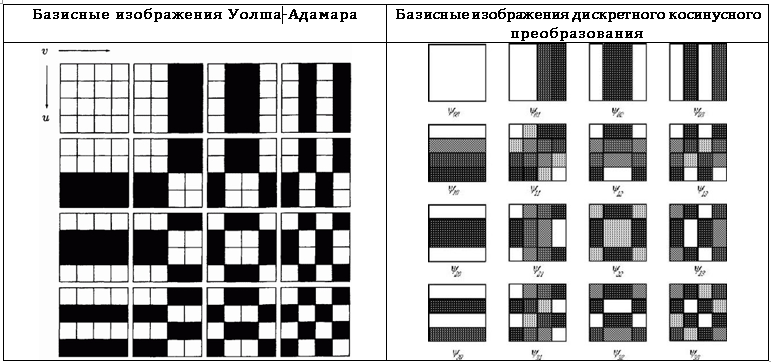
Если эти матрицы расположить в виде квадрата, а полученные значения представить в виде пикселов определённого цвета, можно получить графическое представление базисных функций, т.е. базисные изображения. Базисные изображения преобразования Уолша-Адамара и дискретного косинусного преобразования для n=4 приведены в Табл. 7.
Особенности практической реализации трансформационного кодирования
Общая идея трансформационного кодирования была описана ранее, но, тем не менее, практическая реализация трансформационного кодирования требует прояснения нескольких вопросов.
Перед кодированием изображение разбивается на квадратные блоки, а затем каждый блок подвергается преобразованию. От выбора размера блока зависит как вычислительная сложность, так и итоговая эффективность сжатия. При увеличении размера блока растёт как эффективность сжатия, так и вычислительная сложность, поэтому на практике чаще всего используются блоки размером 8*8 или 16*16 пикселов.
После того, как для каждого блока вычислены коэффициенты преобразования, необходимо их квантовать и закодировать. Наиболее распространёнными подходами являются зональное и пороговое кодирование.
При зональном подходе предполагается, что наиболее информативные коэффициенты будут находиться вблизи нулевых индексов полученного массива. Это значит, что соответствующие коэффициенты должны быть наиболее точно квантованы. Другие коэффициенты можно квантовать значительно грубее или просто отбросить. Проще всего понять идею зонального кодирования можно, посмотрев на соответствующую маску (Табл. 8):
Число в ячейке показывает количество бит, отводимых для кодирования соответствующего коэффициента.
В отличие от зонального кодирования, где для любого блока используется одна и та же маска, пороговое кодирование подразумевает использование уникальной маски для каждого блока. Пороговая маска для блока строится, исходя из следующих соображений: наиболее важными для восстановления исходного изображения являются коэффициенты с максимальным значением, поэтому, сохранив эти коэффициенты и обнулив все остальные, можно обеспечить как высокую степень сжатия, так и приемлемое качество восстановленного изображения. В Табл. 9 показан примерный вид маски для конкретного блока.
Единицы соответствуют коэффициентам, которые будут сохранены и квантованы, а нули соответствуют выброшенным коэффициентам После применения маски полученная матрица коэффициентов должна быть преобразована в одномерный массив, причём для преобразования необходимо использовать обход змейкой. Тогда в полученном одномерном массиве все значимые коэффициенты будут сосредоточены в первой половине, а вторая половина будет практически полностью состоять из нулей. Как было показано в ранее, подобные последовательности весьма эффективно сжимаются алгоритмами кодирования длин серий.
Вейвлет сжатие
Вейвлеты – математические функции, предназначенные для анализа частотных компонент данных. В задачах сжатия информации вейвлеты используются сравнительно недавно, тем не менее исследователям удалось достичь впечатляющих результатов.
В отличие от рассмотренных выше преобразований, вейвлеты не требуют предварительного разбиения исходного изображения на блоки, а могут применяться к изображению в целом. В данном разделе вейвлет сжатие будет пояснено на примере довольно простого вейвлета Хаара.
Для начала рассмотрим преобразование Хаара для одномерного сигнала. Пусть есть набор S из n значений, при преобразовании Хаара каждой паре элементов ставится в соответствие два числа: полусумма элементов и их полуразность. Важно отметить, что это преобразование обратимо: т.е. из пары чисел можно легко восстановить исходную пару. На Рис. 5 показан пример одномерного преобразования Хаара:

Видно, что сигнал распадается на две составляющее: приближенное значение исходного (с уменьшенным в два раза разрешением) и уточняющую информацию.
Двумерное преобразование Хаара – простая композиция одномерных преобразований. Если исходные данные представлены в виде матрицы, то сначала выполняется преобразование для каждой строки, а затем для полученных матриц выполняется преобразование для каждого столбца. На Рис. 6 показан пример двумерного преобразования Хаара.

Цвет пропорционален значению функции в точке (чем больше значение, тем темнее). В результате преобразования получается четыре матрицы: одна содержит аппроксимацию исходного изображения (с уменьшенной частотой дискретизации), а три остальных содержат уточняющую информацию.
Сжатие достигается путём удаления некоторых коэффициентов из уточняющих матриц. На Рис. 7 показан процесс восстановления и само восстановленное изображение после удаления из уточняющих матриц малых по модулю коэффициентов:

Очевидно, что представление изображения с помощью вейвлетов позволяет добиваться эффективного сжатия, сохраняя при этом визуальное качество изображения. Несмотря на простоту, преобразование Хаара сравнительно редко используется на практике, т.к. существуют другие вейвлеты, обладающие рядом преимуществ (например, вейвлеты Добеши или биортогональные вейвлеты).



