Что такое null и как с этим жить: сравнение с null в PHP, тонкости в приведении типов данных
В работе с любыми данными то и дело требуется как-то обозначить их отсутствие. Новички зачастую для этой цели используют значение false, которое, по сути, является не отсутствием данных, а определённым значением типа boolean. Для того, чтобы как-то помечать неопределённость или отсутствие данных, существует специальное значение null. Про false, null и прочее уже немало сказано и добавить что-то оригинальное крайне сложно. Но гораздо сложнее бывает найти баг, вызванный неочевидным поведением этих штуковин. Поэтому, вдохновлённый одним таким багом, самым элегантным в моём послужном списке, я решил написать маленькую шпаргалку на эту тему.
Перегружать пост интересными, но довольно-таки бесполезными определениями из Википедии я не стану. Вместо этого перейду сразу к делу и приведу цитату со страницы php.net, посвящённой null:
До этого момента всё кажется простым, но чтобы так оставалось и дальше, при работе с null нужно придерживаться определённых правил.
Математические операции с null
Во всех математических операциях null ведёт себя аналогично int(0):
Проверка переменной на null
Чтобы точно узнать, что переменная содержит null (то есть, ничего не содержит), нужно использовать либо специальную функцию is_null() либо тождественное сравнение ===, а любые другие способы не подойдут:
Проверка null if-выражениях, а так же в функциях empty() и isset()
Тут переменные с null ведут себя абсолютно предсказуемо, как и любые другие ложные значения (которые в if-выражениях приводятся к false). Но нужно помнить, что это не гарантирует нам, что в переменной находится именно null:
Сравнение двух null
В PHP как гибкое, так и тождественное сравнение двух null всегда возвращает false, в отличие от многих других платформ, где сравнение двух неизвестностей возвращает так же неизвестность (то есть, null).
Поведение null при нетождественном сравнении с приведением типов данных
PHP разрешает сравнивать null-ы не только между собой, но и с другими типами данных. При этом не стоит забывать, что гибкое сравнение в php не является транзитивным, то есть, если два значения равны третьему по отдельности, не гарантирует их равенство между собой. Согласно таблицам приведения типов, гибкое сравнение null при помощи оператора == с разными значениями возвращает разные результаты:
Исследование null в JavaScript (а вместе с ним и загадочного undefined) заслуживает отдельной статьи. Главное отличие состоит в том, что, не смотря на приведение типов, null в JavaScript ничему не равен, кроме самого null и этого самого undefined, хотя в if-выражениях и срабатывает аналогично false. А при сравнении с числами он выдаёт ещё более забавные результаты, чем в PHP.
NULL в MySQL, к примеру, действует гораздо более прямолинейно. Он просто при любых действиях с null (даже при сравнении двух null) возвращает null. С его точки зрения, при любых действиях с неизвестностью в результате получится какая-то другая неизвестность 🙂
Простое правило при работе null, которое помогает избегать проблем
Заметка про NULL
Основные положения
Для удобства сделаем процедуру, печатающую состояние булевого параметра:
и включим опцию печати сообщений на консоль:
Привычные операторы сравнения пасуют перед NULLом:
Сравнение с NULLом
Соответственно, IS NOT NULL действует наоборот: вернёт истину, если значение операнда отлично от NULLа и ложь, если он является NULLом:
DECODE идёт против системы:
Пример с составными индексами находится в параграфе про индексы.
Логические операции и NULL
В большинстве случаев неизвестный результат обрабатывается как ЛОЖЬ :
Отрицание неизвестности даёт неизвестность:
Операторы IN и NOT IN
Для начала сделаем несколько предварительных действий. Для тестов создадим таблицу T с одним числовым столбцом A и четырьмя строками: 1, 2, 3 и NULL
Включим трассировку запроса (для этого надо обладать ролью PLUSTRACE ).
В листингах от трассировки оставлена только часть filter, чтобы показать, во что разворачиваются указанные в запросе условия.
Предварительные действия закончены, давайте теперь поработаем с операторами. Попробуем выбрать все записи, которые входят в набор (1, 2, NULL) :
Попробуем теперь с NOT IN :
Вообще ни одной записи! Давайте разберёмся, почему тройка не попала в результаты запроса. Посчитаем вручную фильтр, который применила СУБД, для случая A=3 :
Из-за особенностей трёхзначной логики NOT IN вообще не дружит с NULLами: как только NULL попал в условия отбора, данных не ждите.
NULL и пустая строка
Здесь Oracle отходит от стандарта ANSI SQL и провозглашает эквивалентность NULLа и пустой строки. Это, пожалуй, одна из наиболее спорных фич, которая время от времени рождает многостраничные обсуждения с переходом на личности, поливанием друг друга фекалиями и прочими непременными атрибутами жёстких споров. Судя по документации, Oracle и сам бы не прочь изменить эту ситуацию (там сказано, что хоть сейчас пустая строка и обрабатывается как NULL, в будущих релизах это может измениться), но на сегодняшний день под эту СУБД написано такое колоссальное количество кода, что взять и поменять поведение системы вряд ли реально. Тем более, говорить об этом они начали как минимум с седьмой версии СУБД (1992-1996 годы), а сейчас уже двенадцатая на подходе.
NULL и пустая строка эквивалентны:
непременный атрибут жёсткого спора:
Длина пустой строки не определена:
Сравнение с пустой строкой невозможно:
Критики подхода, предлагаемого Ораклом, говорят о том, что пустая строка не обязательно обозначает неизвестность. Например, менеджер по продажам заполняет карточку клиента. Он может указать его контактный телефон (555-123456), может указать, что он неизвестен (NULL), а может и указать, что контактный телефон отсутствует (пустая строка). С оракловым способом хранения пустых строк реализовать последний вариант будет проблемно. С точки зрения семантики довод правильный, но у меня на него всегда возникает вопрос, полного ответа на который я так и не получил: как менеджер введёт в поле «телефон» пустую строку и как он в дальнейшем отличит его от NULLа? Варианты, конечно, есть, но всё-таки…
Вообще-то, если говорить про PL/SQL, то где-то глубоко внутри его движка пустая строка и NULL различаются. Один из способов увидеть это связан с тем, что ассоциативные коллекции позволяют сохранить элемент с индексом » (пустая строка), но не позволяют сохранить элемент с индексом NULL:
Использовать такие финты ушами на практике не стоит. Во избежание проблем лучше усвоить правило из доки: пустая строка и NULL в оракле неразличимы.
Математика NULLа
Этот маленький абзац писался пятничным вечером под пиво, на фоне пятничного РЕН-ТВшного фильма. Переписывать его лень, уж извините.
Очевидно, что мы ничем не сможем помочь Коле: неизвестное количество любовников Маши до замужества сводит все расчёты к одному значению — неизвестно. Oracle, хоть и назвался оракулом, в этом вопросе уходит не дальше, чем участники битвы экстрасенсов: он даёт очевидные ответы только на очевидные вопросы. Хотя, надо признать, что Oracle гораздо честнее: в случае с Колей он не будет заниматься психоанализом и сразу скажет: «я не знаю»:
С конкатенацией дела обстоят по другому: вы можете добавить NULL к строке и это её не изменит. Такая вот политика двойных стандартов.
NULL и агрегатные функции
Таблица с данными. Используется ниже много раз:
Пустые значения игнорируются агрегатами:
Набор данных только из NULLов:
Пустой набор данных:
NULL в OLAP
Удобная фишка sqlplus: при выводе данных заменяет NULL на указанную строку:
Проверяем дуализм NULLа в многомерном кубе:
Нельзя использовать null в операциях сравнения
Пожалуйста обратите внимание, что в СУБД Firebird версий до 2.0 чаще всего недопустимо прямое использование константы NULL в операциях и сравнениях. Если вы видите NULL в приведенных ниже выражениях, понимайте это как « значение поля, переменной или другого выражения, результат вычисления которого есть NULL ».
Выражения, возвращающие NULL
Выражения в этом списке всегда возвратят NULL :
‘Home ‘ || ‘sweet ‘ || NULL
NULL в логических выражениях
NULL or false = NULL
NULL or true = true
NULL or NULL = NULL
NULL and false = false
NULL and true = NULL
NULL and NULL = NULL
Все эти результаты находятся в соответствии с булевой логикой. Факт состоит в том, что в порядке вычисления « X or true » и « X and false » вам просто нет необходимости знать значение X, что так же базируется на известной особенности, которую мы знаем в различных языках программирования под названием « сокращенное (ускоренное) вычисление булевых выражений ».
Больше логики (или нет)
Полученные выше результаты сокращенного вычисления могут привести вас к следующим идеям:
Пустая строка располагается лексикографически перед любой другой строкой. Поэтому, S >= » равно true не зависимо от значения S.
Как это реализовано в СУБД Firebird? Что ж, мне очень жаль, но я должен сообщить вам, что, несмотря на такую неотразимую логику и аналогию с результатами булевых операций, описанных выше, следующие выражения всегда дают в итоге NULL :
A = A (если A является полем или переменной со значением NULL )
Это сделано, чтобы быть последовательными.
NULL в агрегатных функциях
| ID | Name | Amount |
|---|---|---|
| 1 | John | 37 |
| 2 | Jack | NULL > |
| 3 | Joe | 5 |
| 4 | Josh | 12 |
| 5 | Jay | NULL > |
NULL поля в MySQL
Вступление
Часто на форумах и даже в учебниках пишут о том, что лучше не использовать NULL поля в MySQL. В этих утверждениях смущает тот факт, что никто не удосуживается объяснить, почему NULL – это зло. Эта заметка призвана разобраться, что такое NULL в MySQL и так ли страшен чёрт, как его малюют.
Что такое NULL?
Наряду с множеством типов данных в БД, NULL стоит особняком. NULL означает отсутствие значения.
Зачем использовать особый тип данных для того, чтоб указать отсутствие значения, когда можно просто вставить пустую строку, например? Этот вопрос мне всегда казался глупым, и я удивляюсь тому, как в книгах и статьях уделяют ему достаточное количество внимания.
Чем опасен NULL?
Сравнение NULL с любым другим значением, даже с родственным (в большинстве языков программирования, в частности, в PHP null, 0, false это одно и то же, если не применять строгого сравнения, которое включает сравнение типов) ему FALSE вернёт NULL. Отсюда следует первая ловушка.
Допустим, у нас есть таблица:
Добавим в неё 2 записи:
INSERT INTO users (name, family) VALUES(‘Андрей’, ‘Романов’), (‘Иван’, NULL);
В случае, если вы захотите объединить имя и фамилию, получив ФИО одним полем, например, таким запросом:
SELECT CONCAT(name, ‘ ‘, family) FROM `users`
MySQL не оправдает ваших ожиданий. Вы получите NULL вместо Ивана.

Немного неожиданно, правда?
На деле же ничего неожиданного нет, если вы помните, что любая операция с NULL вернёт NULL, кроме специальных операций, предназначенных для работы с NULL: IS NULL, IS NOT NULL, IFNULL()
Сортировка по NULL
Всего лишь хочу опровергнуть некоторые фразы из русского мануала MySQL о том, что при сортировке по столбцу, содержащим NULL значения, эти самые NULL значиния всега оказываются наверху. Это не так.
SELECT name, family FROM `users` ORDER BY family ASC

SELECT name, family FROM `users` ORDER BY family DESC

Как видим, NULL считается наименьшим значением, и порядок сортировки на него действует.
Группировки и NULL
Все просто.
MySQL группирует по NULL так же как и по любому другому полю.
Добавим нашей таблице users столбец score INT UNSIGNED NULL;

Подсчитаем сколько всего пользователей набрали то или иное количество очков, т.е. сгруппируем выборку по полю score
SELECT COUNT(*), score FROM `users` GROUP BY score

Как видно, MySQL сгруппировала 2 строки с score = NULL
Индексы и NULL
Откуда-то ходит заблуждение о том, что MySQL не использует индексы, если столбец может принимать значения NULL.
Это не так!
Проведём несколько экспериментов.
Выберем все записи, где score = NULL. Не забываем, что мы для этого должны использовать конструкцию IS NULL
EXPLAIN SELECT * FROM `users` WHERE score IS NULL

Индекс используется.
Выберем все записи, где количество очков больше, например, пяти.
EXPLAIN SELECT * FROM `users` WHERE `score` > 5

Индекс используется.
Найдем пользователя, у которого ровно 7 очков
EXPLAIN SELECT * FROM `users` WHERE `score` = 7

Индекс используется.
Можно сделать вывод: заблуждение действительно таковым и оказалось.
Можно смело использовать NULL-поля при создании индекса и индекс будет работать.
Когда следует использовать NULL?
Ранее я привел пример таблицы сайтов, которая содержит поле PR.
PR – это целочисленное значение, которое может принимать значение 0, к тому же оно может быть в состоянии «не посчитано». Как реализовать хранение такого свойства в таблице?
Зачем отказываться от того, что язык предлагает тебе «из коробки»?
Значение NULL для такого поля подходит идеально. NULL – означает «нет значения», т.е. оно ещё не посчитано. Если значение равно нулю, значит оно действительно равно нулю. Все просто.
Второй пример подходящего случая для использования NULL – это поле-потомок.
Поле-потомок указывает на id записи из другой (или же этой же таблицы). Примером такого поля может быть parent_id.
Выводы
Нет причин бояться создания NULL полей. Надо хорошо понимать, что NULL в MySQL это не ноль и не false – это отсутствие значения. Надо знать, как MySQL работает с NULL: нюансы есть, но их не много. У MySQL нет проблем с индексацией NULL полей.
Обработка значений NULL
Значения NULL и тройственная логика
Разрешение значений NULL в определениях столбцов вводит в приложение логику трех значений. Результатом сравнения может быть одно из трех условий:
Так как значение NULL считается неизвестным, два значения NULL, сравниваемые друг с другом, не считаются равными. В выражениях, использующих арифметические операторы, если какой-либо из операндов имеет значение NULL, результат также равен NULL.
Значения NULL и SqlBoolean
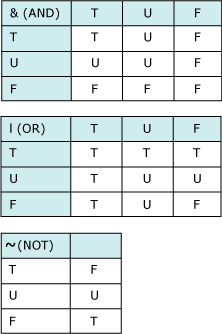
При сравнении между любыми типами System.Data.SqlTypes будет возвращаться значение SqlBoolean. Функция IsNull для каждого типа SqlType возвращает SqlBoolean и может использоваться для проверки на наличие значений NULL. В следующих таблицах истинности показано, как работают операторы AND, OR и NOT при наличии значения NULL. (T = true, F = false и U = неизвестно или NULL.)
Основные сведения о параметре ANSI_NULLS
Стандарт ANSI SQL-92 не поддерживает columnName = NULL в предложении WHERE. В SQL Server параметр ANSI_NULLS управляет допустимостью значений NULL по умолчанию в базе данных и вычислением сравнений со значениями NULL. Если параметр ANSI_NULLS включен (по умолчанию), то при проверке на наличие значений NULL в выражениях должен использоваться оператор IS NULL. Например, результатом следующего сравнения всегда является неизвестность при включенном параметре ANSI_NULLS:
Сравнение с переменной, содержащей значение NULL, также приводит к неизвестному результату:
Для тестирования на значение NULL используются предикаты IS NULL и IS NOT NULL. Это может усложнить предложение WHERE. Например, столбец TerritoryID в таблице AdventureWorks Customer допускает значения NULL. Если инструкция SELECT используется для тестирования на значения NULL в дополнение к другим, она должна включать предикат IS NULL:
Если в SQL Server параметр ANSI_NULLS отключен, можно создать выражения, которые используют оператор равенства для сравнения со значением NULL. Однако нельзя запретить другим подключениям задавать параметры NULL для этого подключения. Использование параметра IS NULL для проверки на наличие значений NULL всегда работает, независимо от установленного значения ANSI_NULLS для подключения.
Присвоение значений Null
Значения NULL являются специальными, и их семантика хранения и назначения различается в разных системах типов и системах хранения. Dataset предназначен для использования с различными системами типов и хранения.
В этом разделе описывается семантика значений NULL для присвоения значений NULL для DataColumn в DataRow в различных системах типов.
Значение по умолчанию для любого экземпляра System.Data.SqlTypes— NULL.
Значения NULL могут быть назначены DataColumn, как показано в следующем примере кода. Вы можете напрямую назначить значения NULL для переменных SqlTypes без запуска исключения.
Пример
В следующем примере кода показано создание DataTable с двумя столбцами, определенными как SqlInt32 и SqlString. Код добавляет одну строку известных значений, одну строку значений NULL, а затем выполняет итерацию по DataTable, присваивая значения переменным и отображая выходные данные в окне консоли.
В этом примере отображаются следующие результаты:
Присвоение для многих столбцов или строк
Кроме того, следующие правила применяются к экземпляру назначений NULL DataRow.[«columnName»] :
Значение по умолчанию — DbNull.Value для всех, за исключением строго типизированных столбцов со значением NULL, где он является соответствующим строго типизированным значением NULL.
Значения NULL никогда не записываются во время сериализации в XML-файлы (как в xsi:nil).
Все значения, в том числе по умолчанию, отличные от NULL, всегда записываются при сериализации в XML. Это отличается от семантики XSD/XML, где значение NULL (xsi: nil) является явным, а значение по умолчанию — неявным (если отсутствует в XML, то проверяющее средство синтаксического анализа может получить его из связанной схемы XSD). Обратное верно для DataTable : значение NULL является неявным, а значение по умолчанию — явным.
Всем отсутствующим значениям столбцов для строк, считываемых из входных данных XML, присваивается значение NULL. Строкам, созданным с помощью NewRow или аналогичных методов, присваивается значение по умолчанию DataColumn.



