Методы, применяемые для решения задач классификации
Для классификации используются различные методы:
1. классификация с помощью деревьев решений;
Метод деревьев решений для задачи состоит в том, чтобы осуществлять процесс деления исходных данные на группы, пока не будут получены однородные (или почти однородные) их множества. Процесс продолжается до тех пор, пока не выполнится критерий остановки. Это возможно в следующих ситуациях:
¾ Все (или почти все) данные данного узла принадлежат одному и тому же классу;
¾ Не осталось признаков, по которым можно построить новое разбиение;
¾ Дерево превысило заранее заданный «лимит роста» (если таковой был заранее установлен).
Совокупность правил, которые дают такое разбиение, позволят затем делать прогноз (т.е. определять наиболее вероятный номер класса) для новых данных.
Примеры задач классификации, решаемых методом деревьев:
¾ скоринговые модели кредитования (англ.: credit scoring models);
¾ маркетинговые исследования, направленные на выявление предпочтений клиента или степени его удовлетворённости – обычно эти сведения бывают востребованы маркетинговыми агентствами или рекламными компаниями;
¾ диагностика (медицинская или техническая), где по набору значений факторов (симптомов, результатов анализов) нужно поставить диагноз или сделать вывод о динамике процесса.
2. байесовская (наивная) классификация;
«Наивной» она называется потому, что исходит из предположения о взаимной независимости признаков.
Свойства наивной классификации:
¾ Использование всех переменных и определение всех зависимостей между ними.
¾ Наличие двух предположений относительно переменных:
¾ все переменные являются одинаково важными;
¾ все переменные являются статистически независимыми, т.е. значение одной переменной ничего не говорит о значении другой.
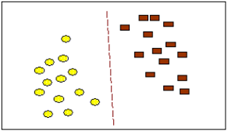
3. классификация методом опорных векторов;
При помощи данного метода решаются задачи бинарной классификации.
В основе метода лежит понятие плоскостей решений.
Плоскость (plane) решения разделяет объекты с разной классовой принадлежностью.
4. классификация при помощи метода ближайшего соседа;
Следует сразу отметить, что метод «ближайшего соседа» («nearest neighbour») относится к классу методов, работа которых основывается на хранении данных в памяти для сравнения с новыми элементами. При появлении новой записи для прогнозирования находятся отклонения между этой записью и подобными наборами данных, и наиболее подобная (или ближний сосед) идентифицируется.
Например, при рассмотрении нового клиента банка, его атрибуты сравниваются со всеми существующими клиентами данного банка (доход, возраст и т.д.). Множество «ближайших соседей» потенциального клиента банка выбирается на основании ближайшего значения дохода, возраста и т.д.
5. статистические методы, в частности, линейная регрессия;
Математическое уравнение, которое оценивает линию простой линейной регрессии:
х – называется предиктором – независимой или объясняющей переменной.
Для данной величины х, Y — значение переменной у (называемой зависимой, выходной переменной, или переменной отклика), которое расположено на линии оценки. Это есть значение, которое мы ожидаем для у (в среднем), если мы знаем величину х, и называется она «предсказанное значение у» (рис. 5).
а – свободный член (пересечение) линии оценки; это значение Y, когда х = 0.
b – угловой коэффициент или градиент оценённой линии; он представляет собой величину, на которую Y увеличивается в среднем, если мы увеличиваем х на одну единицу (рис. 5). Коэффициент b называют коэффициентом регрессии.
Например: при увеличении температуры тела человека на 1оС, частота пульса увеличивается в среднем на 10 ударов в минуту.
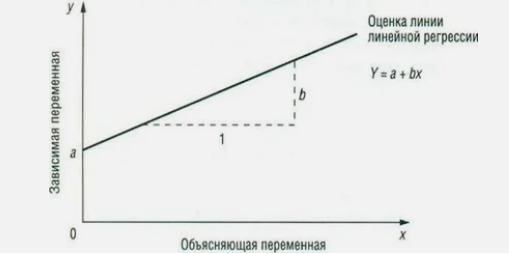
Рисунок 5. Линия линейной регрессии, показывающая коэффициент а и угловой коэффициент b (величину возрастания Y при увеличении х на одну единицу)
Математически решение уравнения линейной регрессии сводится к вычислению параметров а и b таким образом, чтобы точки исходных данных корреляционного поля как можно ближе лежали к прямой регрессии.
6. классификация при помощи искусственных нейронных сетей;
Искусственные нейронные сети как средство обработки информации моделировались по аналогии с известными принципами функционирования биологических нейронных сетей. Их структура базируется на следующих допущениях:
¾ сигналы между нейронами передаются по связям от выходов ко входам;
¾ каждая связь характеризуется весом, на который умножается передаваемый по ней сигнал;
¾ каждый нейрон имеет активационную функцию (как правило, нелинейную), аргумент которой рассчитывается как сумма взвешенных входных сигналов, а результат считается выходным сигналом.
Таким образом, нейронные сети представляют собой наборы соединенных узлов, каждый из которых имеет вход, выход и активационную функцию (как правило, нелинейную). Они обладают способностью обучаться на известном наборе примеров обучающего множества. Обученная нейронная сеть представляет собой «черный ящик» (нетрактуемую или очень сложно трактуемую прогностическую модель), которая может быть применена в задачах классификации, кластеризации и прогнозирования.
7. классификация при помощи генетических алгоритмов.
Первый шаг при построении генетических алгоритмов — это кодировка исходных логических закономерностей в базе данных, которые именуют хромосомами, а весь набор таких закономерностей называют популяцией хромосом. Далее для реализации концепции отбора вводится способ сопоставления различных хромосом. Популяция обрабатывается с помощью процедур репродукции, изменчивости (мутаций), генетической композиции. Эти процедуры имитируют биологические процессы.
Генетические алгоритмы имеют ряд недостатков. Критерий отбора хромосом и используемые процедуры являются эвристическими и далеко не гарантируют нахождения “лучшего” решения. Как и в реальной жизни, эволюцию может “заклинить” на какой-либо непродуктивной ветви.
Дата добавления: 2020-04-25 ; просмотров: 114 ; Мы поможем в написании вашей работы!
Задача классификации
Задача классифика́ции — формализованная задача, в которой имеется множество объектов (ситуаций), разделённых некоторым образом на классы. Задано конечное множество объектов, для которых известно, к каким классам они относятся. Это множество называется выборкой. Классовая принадлежность остальных объектов не известна. Требуется построить алгоритм, способный классифицировать (см. ниже) произвольный объект из исходного множества.
Классифици́ровать объект — значит, указать номер (или наименование) класса, к которому относится данный объект.
Классифика́ция объекта — номер или наименование класса, выдаваемый алгоритмом классификации в результате его применения к данному конкретному объекту.
В математической статистике задачи классификации называются также задачами дискриминантного анализа. В машинном обучении задача классификации решается, как правило, с помощью методов искусственных нейронных сетей при постановке эксперимента в виде обучения с учителем.
Существуют также другие способы постановки эксперимента — обучение без учителя, но они используются для решения другой задачи — кластеризации или таксономии. В этих задачах разделение объектов обучающей выборки на классы не задаётся, и требуется классифицировать объекты только на основе их сходства друг с другом. В некоторых прикладных областях, и даже в самой математической статистике, из-за близости задач часто не различают задачи кластеризации от задач классификации.
Некоторые алгоритмы для решения задач классификации комбинируют обучение с учителем с обучением без учителя, например, одна из версий нейронных сетей Кохонена — cети векторного квантования, обучаемые с учителем.
Содержание
Математическая постановка задачи
Пусть  — множество описаний объектов,
— множество описаний объектов,  — множество номеров (или наименований) классов. Существует неизвестная целевая зависимость — отображение
— множество номеров (или наименований) классов. Существует неизвестная целевая зависимость — отображение  , значения которой известны только на объектах конечной обучающей выборки
, значения которой известны только на объектах конечной обучающей выборки  . Требуется построить алгоритм
. Требуется построить алгоритм  , способный классифицировать произвольный объект
, способный классифицировать произвольный объект  .
.
Вероятностная постановка задачи
Более общей считается вероятностная постановка задачи. Предполагается, что множество пар «объект, класс»  является вероятностным пространством с неизвестной вероятностной мерой
является вероятностным пространством с неизвестной вероятностной мерой  . Имеется конечная обучающая выборка наблюдений , сгенерированная согласно вероятностной мере . Требуется построить алгоритм , способный классифицировать произвольный объект .
. Имеется конечная обучающая выборка наблюдений , сгенерированная согласно вероятностной мере . Требуется построить алгоритм , способный классифицировать произвольный объект .
Признаковое пространство
Признаком называется отображение  , где
, где  — множество допустимых значений признака. Если заданы признаки
— множество допустимых значений признака. Если заданы признаки  , то вектор
, то вектор  называется признаковым описанием объекта . Признаковые описания допустимо отождествлять с самими объектами. При этом множество
называется признаковым описанием объекта . Признаковые описания допустимо отождествлять с самими объектами. При этом множество  называют признаковым пространством.
называют признаковым пространством.
В зависимости от множества  признаки делятся на следующие типы:
признаки делятся на следующие типы:
Часто встречаются прикладные задачи с разнотипными признаками, для их решения подходят далеко не все методы.
Типология задач классификации
Типы входных данных
Классификацию сигналов и изображений называют также распознаванием образов.
Методы классификации и прогнозирования. Деревья решений
Преимущества деревьев решений
Интуитивность деревьев решений. Классификационная модель, представленная в виде дерева решений, является интуитивной и упрощает понимание решаемой задачи. Результат работы алгоритмов конструирования деревьев решений, в отличие, например, от нейронных сетей, представляющих собой «черные ящики», легко интерпретируется пользователем. Это свойство деревьев решений не только важно при отнесении к определенному классу нового объекта, но и полезно при интерпретации модели классификации в целом. Дерево решений позволяет понять и объяснить, почему конкретный объект относится к тому или иному классу.
Деревья решений позволяют создавать классификационные модели в тех областях, где аналитику достаточно сложно формализовать знания.
Алгоритм конструирования дерева решений не требует от пользователя выбора входных атрибутов (независимых переменных). На вход алгоритма можно подавать все существующие атрибуты, алгоритм сам выберет наиболее значимые среди них, и только они будут использованы для построения дерева. В сравнении, например, с нейронными сетями, это значительно облегчает пользователю работу, поскольку в нейронных сетях выбор количества входных атрибутов существенно влияет на время обучения.
Разработан ряд масштабируемых алгоритмов, которые могут быть использованы для построения деревьев решения на сверхбольших базах данных; масштабируемость здесь означает, что с ростом числа примеров или записей базы данных время, затрачиваемое на обучение, т.е. построение деревьев решений, растет линейно. Примеры таких алгоритмов: SLIQ, SPRINT.
Быстрый процесс обучения. На построение классификационных моделей при помощи алгоритмов конструирования деревьев решений требуется значительно меньше времени, чем, например, на обучение нейронных сетей.
Большинство алгоритмов конструирования деревьев решений имеют возможность специальной обработки пропущенных значений.
Процесс конструирования дерева решений
Рассмотрим эти вопросы подробней.
Критерий расщепления
В некоторых методах для выбора атрибута расщепления используется так называемая мера информативности подпространств атрибутов, которая основывается на энтропийном подходе и известна под названием «мера информационного выигрыша» (information gain measure) или мера энтропии.
Если дано множество T, включающее примеры из n классов, индекс Gini, т.е. gini(T), определяется по формуле:

Большое дерево не означает, что оно «подходящее»
В процессе построения дерева, чтобы его размеры не стали чрезмерно большими, используют специальные процедуры, которые позволяют создавать оптимальные деревья, так называемые деревья «подходящих размеров» (Breiman,1984).
Какой размер дерева может считаться оптимальным? Дерево должно быть достаточно сложным, чтобы учитывать информацию из исследуемого набора данных, но одновременно оно должно быть достаточно простым [39]. Другими словами, дерево должно использовать информацию, улучшающую качество модели, и игнорировать ту информацию, которая ее не улучшает.
Тут существует две возможные стратегии. Первая состоит в наращивании дерева до определенного размера в соответствии с параметрами, заданными пользователем. Определение этих параметров может основываться на опыте и интуиции аналитика, а также на некоторых «диагностических сообщениях» системы, конструирующей дерево решений.
Вторая стратегия состоит в использовании набора процедур, определяющих «подходящий размер» дерева, они разработаны Бриманом, Куилендом и др. в 1984 году. Однако, как отмечают авторы, нельзя сказать, что эти процедуры доступны начинающему пользователю.
Процедуры, которые используют для предотвращения создания чрезмерно больших деревьев, включают: сокращение дерева путем отсечения ветвей ; использование правил остановки обучения.
Остановка построения дерева
Сокращение дерева или отсечение ветвей
Качество классификационной модели, построенной при помощи дерева решений, характеризуется двумя основными признаками: точностью распознавания и ошибкой.
Точность распознавания рассчитывается как отношение объектов, правильно классифицированных в процессе обучения, к общему количеству объектов набора данных, которые принимали участие в обучении.
Ошибка рассчитывается как отношение объектов, неправильно классифицированных в процессе обучения, к общему количеству объектов набора данных, которые принимали участие в обучении.
Решение задачи классификации с помощью нейронной сети и Python
Задача классификации встречается довольно часто, но при решении каждой конкретной задачи встречаются свои сложности. Поэтому сегодня мы посмотрим, можно ли решить задачу классификации не с помощью стандартных методов машинного обучения, а с помощью нейронной сети и при этом получить хороший результат классификации. На входе имеем результаты работы нейронной сети, которая определяла объекты, находящиеся на изображении с камеры – 12 классов изображений и 35 типов объектов, которые были найдены на изображениях.

Задача:
1. Подготовить данные для работы нейронной сети.
2. Обучить нейронную сеть определять класс изображения по найденным объектам.
3. Проверить обученную нейронную сеть на тестовой выборке.
Для решения данной задачи будем использовать библиотеки tensorflow, pandas и numpy.
Сначала достанем из имени файла название класса и отсортируем записи в таблице.
Также нормализуем значения из выборки и заполним пустые ячейки нулями.
Следующий шаг – заменить имя класса на числовой вектор из 0 и 1. Вектор будет содержать одну 1 и одиннадцать 0 и показывать вероятность принадлежности к конкретному классу. А чтобы разделить выборку, считаем количество записей, относящихся к каждому классу, и делим данные в соотношении 60/40 соответственно.
Теперь необходимо построить модель нейронной сети. На вход ей будет подаваться 35 чисел – нормированное количество объектов на изображении, на выходе будет 12 чисел – вероятность принадлежности к каждому классу. Используем наиболее распространенную функцию активации «relu» и функцию потерь MSE (среднюю квадратическую ошибку), при которой нейронная сеть выдает лучший результат. Также добавим слой Dropout, чтобы предотвратить переобучение модели.
Построим графики обучения нашей модели – график потерь (Model loss) и график точности (Model accuracy). По вертикали изменение параметра, по горизонтали – количество эпох обучения. Как видно из графиков, Потери приближаются к 0, а точность приближается к 1.


Чтобы использовать модель в дальнейшем сохраним ее в специальном формате h5.
После обучения модели, проверим ее на тестовой выборке. Получаем следующие результаты:

Получаем, что правильно классифицировали 90% всех случаев. Класс pomeschenie_pered_htsk содержал меньше всего объектов, поэтому нейронная сеть не смогла определить его на тестовой выборке.
Что предпринималось, чтобы улучшить результат работы нейронной сети?
Вывод: задачу классификации можно также успешно решать с помощь нейронной сети – главное подготовить исходные данные и настроить параметры нейронной сети.
WEKA. Решение задачи классификации с помощью методов машинного обучения
Благодаря машинному обучению, в аудиторской практике появилась возможность проверки больших массивов данных путем комплексного автоматического анализа признаков для нахождения закономерностей и составления прогнозов без привлечения человеческих ресурсов.
Одна из распространенных задач – задача классификации, в рамках которой необходимо получить категориальный ответ на основе набора признаков: по составу почвы определить, в какой широте был взят образец, определить категорию надежности клиента банка и многое другое.
Для решения подобного рода задач существует множество инструментов и библиотек, одну из которых мы попробуем использовать для решения простой задачи классификации текста.
В процессе выбора инструмента мы остановились на WEKA – наборе инструментов машинного обучения на языке Java для решения задач интеллектуального анализа данных и машинного обучения. Среди возможностей фреймворка можно выделить предварительную обработку данных, алгоритмы классификации, регрессии и кластеризации, правила ассоциации и визуализацию.
Рассмотрим работу с фреймворком на примере простой задачи: по описанию постройки необходимо определить ее тип.

Используя этот класс загружаем тренировочную и тестовую выборку данных.
Если данные были загружены без предварительной обработки – необходимо ее выполнить уже внутри фреймворка. Один из способов предобработки данных – нормализация. Нормализация применяется для приведения признаков к некоторому заданному диапазону. Это позволяет сводить признаки в одной модели для ее корректной работы.
Нормализация данных в WEKA происходит через класс Normalize():
После подготовки датасетов можно переходить к созданию классификатора:
Необходимо определиться с алгоритмом классификации. Для задачи классификации текста из имеющихся у фреймворка алгоритмов классификации больше других подходит алгоритм полиномиальной наивной Байесовской классификации. Он обеспечивает простой способ создания точных моделей с очень хорошими характеристиками, учитывая его простоту.
Принцип работы алгоритма заключается в вычислении вероятности наступления некоторых событий, учитывая вероятности «предыдущих» событий.
В полиномиальной модели событий векторы признаков представляют частоты, с которыми определенные события были сгенерированы полиномиальным распределением (p_1, …, p_n) где p_i — это вероятность того, что произойдет событие i (или K таких многочленов в случае мультикласса). Вектор признаков (x_1, …, x_n) это гистограмма, где x_i подсчитывает, сколько раз событие i наблюдалось в конкретном случае. Это модель событий, обычно используемая для классификации документов, с событиями, представляющими появление слова в одном документе.
Алгоритм реализован через класс NaiveBayesMultinomial(). Для фильтрации параметров классификатора этот класс оборачивается метаклассом FilteredClassifier() — класс для запуска произвольного классификатора данных, прошедших произвольный фильтр. Как и классификатор, структура фильтра основана исключительно на обучающих данных, и тестовые экземпляры будут обрабатываться фильтром без изменения их структуры.
Перед обучением модели классификации при помощи фильтра задаются алгоритм и правила токенизации текста через классы StringToWordVector() – фильтр для токенизации параметров и NGramTokenizer() – класс, преобразующий текст в N-граммы.
Затем полученный фильтр применяется к классификатору и вызывается метод классификатора buildClassifier() для обучения на тестовом наборе данных.
После этих манипуляций можно провести оценку полученной модели классификации на тестовом наборе данных.
Оценка модели происходит через класс Evaluation(). Необходимо передать в конструктор обучающую выборку, а в метод валидации – тестовую.
Для вывода оценочных характеристик модели используется метод класса toSummaryString():

После того как точность модели будет посчитана удовлетворительной – модель можно сохранять и использовать:
В результате обучения мы получили модель, подходящую для решения нашей задачи. По текстовому описанию объекта он был классифицирован как «Дом»:

По результатам применения фреймворка можно сделать некоторые выводы.
Поставленную задачу фреймворк решил полностью, в дальнейшем мы попробуем использовать другие алгоритмы и поделимся своими наблюдениями. Спасибо за внимание!



